






lmm-evaluation Computer Vision Project
Roboflow
Updated a year ago
3
views0
downloadsTags
Description
This project contains the images Roboflow uses to evaluate the capabilities of Large Multimodal Models (LMMs) such as GPT-4 with Vision and Gemini.
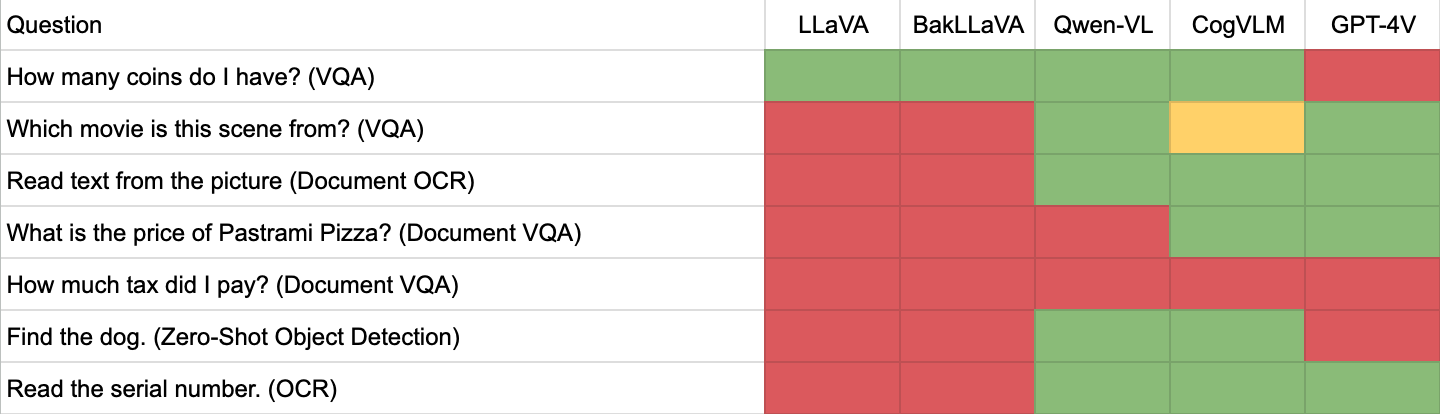
This project contains seven images, which we pass through LMMs with the prompts listed below. The task type each prompt investigates is in parenthesis.
coins.jpeg: How many coins do I have? (Visual Question Answering (VQA))kevin.png: Which movie is this scene from? (VQA)ocr.png: Read text from the picture. (Document OCR)pizza.jpg: What is the price of Pastrami Pizza? (Document VQA)receipg.jpeg: How much tax did I pay? (Document VQA)simple-doge.jpeg: Find the dog. (Zero-shot object detection)tire.jpg: Read the serial number. (VQA)
LMM Evaluations
Blog posts in which this dataset is featured:
Model Comparison
Build Computer Vision Applications Faster with Supervision
Visualize and process your model results with our reusable computer vision tools.
Cite This Project
If you use this dataset in a research paper, please cite it using the following BibTeX:
@misc{
lmm-evaluation_dataset,
title = { lmm-evaluation Dataset },
type = { Open Source Dataset },
author = { Roboflow },
howpublished = { \url{ https://universe.roboflow.com/roboflow-gw7yv/lmm-evaluation } },
url = { https://universe.roboflow.com/roboflow-gw7yv/lmm-evaluation },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2023 },
month = { dec },
note = { visited on 2024-12-22 },
}